
How to Install and Run Apache Hadoop on AWS EC2 (Single-Node-Cluster)
Introduction
In this blog, I’ll guide you through the steps to install and run Apache Hadoop on an AWS EC2 instance as a single-node cluster. If you haven’t set up an EC2 instance yet, check out my previous Blog->Guide to creating an EC2 instance before proceeding.
Prerequisites
- An active AWS account
- An EC2 instance (preferably Ubuntu)
- Basic knowledge of Linux command line
Step 1: Update and Install Java
First, make sure your EC2 instance is up-to-date and install OpenJDK 11.
sudo apt update
sudo apt install openjdk-11-jdk -y
java -version
Check if Java is installed correctly using the java -version command.
Step 2: Download and Extract Hadoop
Next, download Hadoop 3.4.0 and extract the tarball:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
tar -xvf hadoop-3.4.0.tar.gz
mv hadoop-3.4.0 hadoop
This will create a directory called hadoop containing the Hadoop binaries.
Step 3: Set Up Environment Variables
Configure the Hadoop environment variables by editing the .bashrc file:
vi ~/.bashrc
Add the following lines:
export HADOOP_HOME=/home/ubuntu/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Save the file and apply the changes:
source ~/.bashrc
Step 4: Configure Hadoop Files
Navigate to the Hadoop configuration directory:
cd $HADOOP_HOME/etc/hadoop
ls
4.1 Edit core-site.xml
Configure the HDFS URL in the core-site.xml file:
vi core-site.xml
Add the following content:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ec2-44-223-67-165.compute-1.amazonaws.com:9000</value>
</property>
</configuration>
change the PUBLIC DNS to your DNS Which u can find in Ec2 Dashboard Replace this
4.2 Edit hdfs-site.xml
Set up the namenode and datanode directories:
vi hdfs-site.xml
Add the following:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/ubuntu/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/ubuntu/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
4.3 Edit yarn-site.xml
Configure YARN in the yarn-site.xml file:
vi yarn-site.xml
Add the following configuration:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ec2-44-223-67-165.compute-1.amazonaws.com</value>
</property>
</configuration>
change the PUBLIC DNS to your DNS Which u can find in Ec2 Dashboard Replace this
4.4 Edit mapred-site.xml
Configure MapReduce in the mapred-site.xml file:
vi mapred-site.xml
Add the following lines:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>ec2-44-223-67-165.compute-1.amazonaws.com:8021</value>
</property>
</configuration>
change the PUBLIC DNS to your DNS Which u can find in Ec2 Dashboard Replace this
Step 5: Update /etc/hosts
Update the /etc/hosts file to map the local IP address to your EC2 hostname:
sudo vi /etc/hosts
Remove the line with 127.0.0.1 localhost and add the following:
172.31.87.190 ec2-3-83-109-16.compute-1.amazonaws.com
Step 6: Add JAVA path
Update the Java path in cd $HADOOP_HOME/etc/hadoop and add the
JAVA PATH
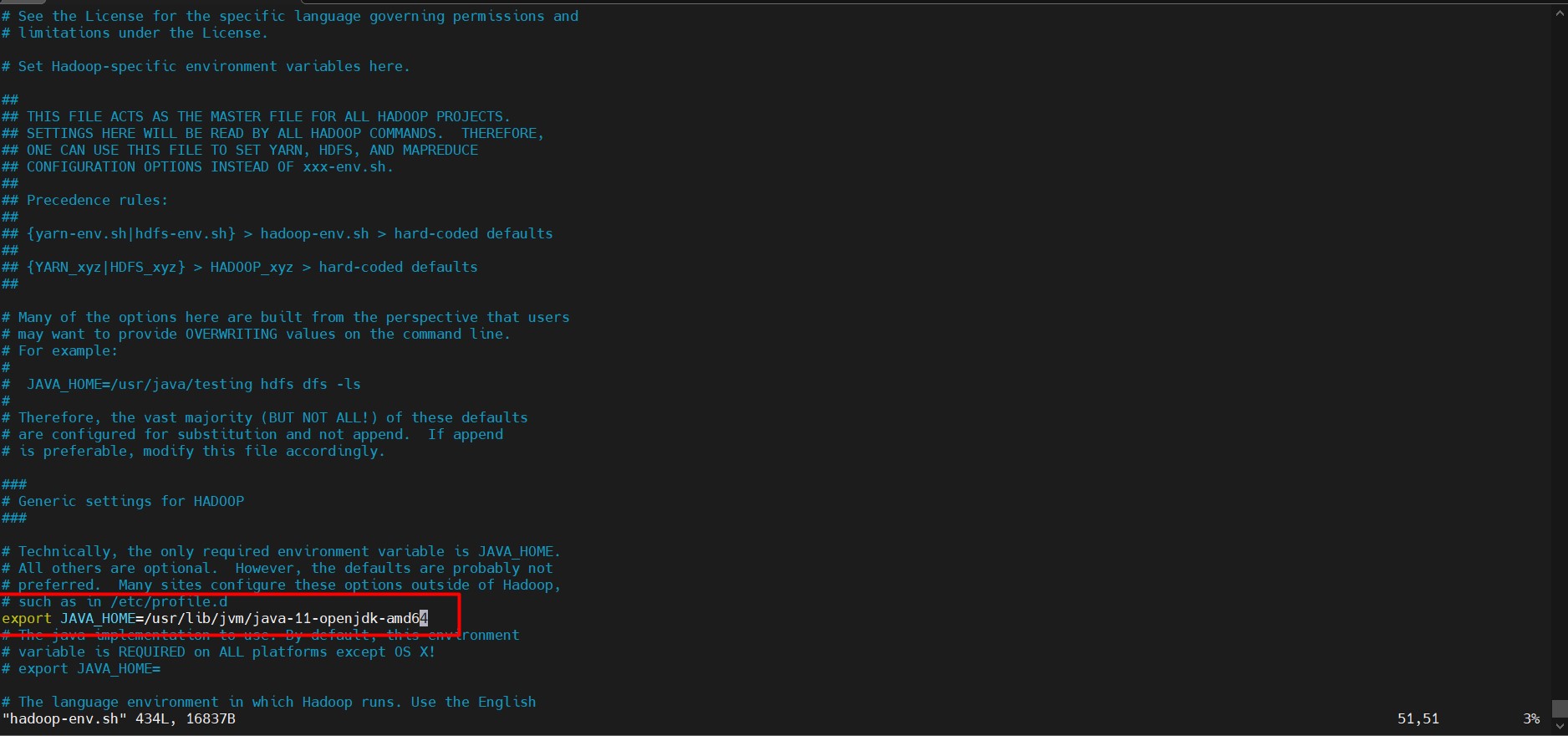
vi hadoop-env.sh
Remove # and paste this export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Step 7: ssh key adding for (NOT ROOT USER)
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod og-wx ~/.ssh/authorized_keys
Step 8: Start Hadoop
Navigate to the Hadoop sbin directory:
cd $HADOOP_HOME/sbin
Start all Hadoop services:
./start-all.sh
Check if all processes are running using:
jps
Format the Namenode:
hadoop namenode -format
Finally, start the distributed file system:
start-dfs.sh
Conclusion
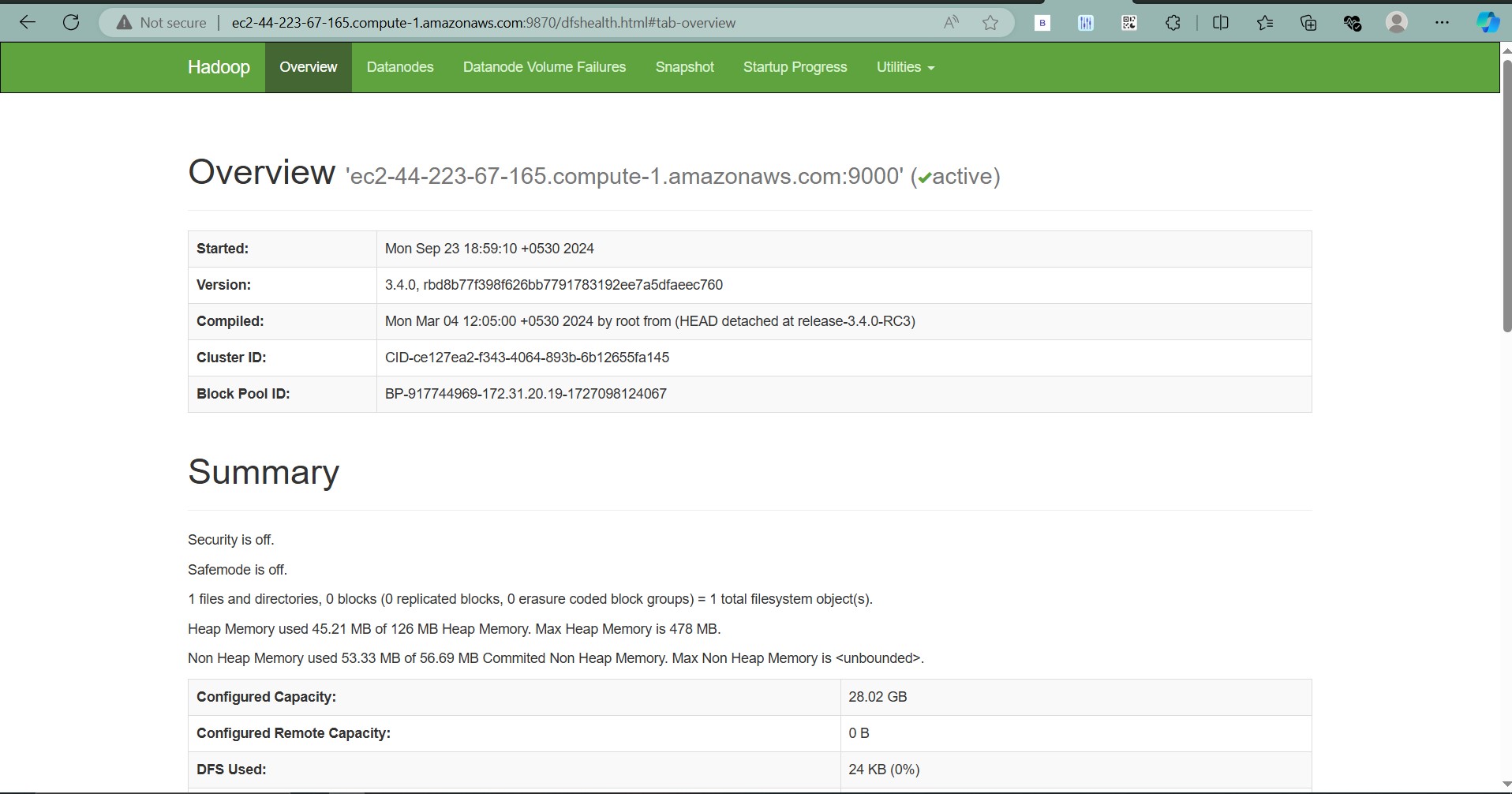
That’s it! You now have Apache Hadoop running on a single-node cluster on your EC2 instance. You can access the NameNode UI by visiting http://<ec2-public-ip>:9870.
##Reference images
Leave a comment